
Introduction to Linux Filter Commands
As per the user requirement the linux filter commands will read the standard inputs, performs the necessary actions or operations on top of it and writes the end result to the standard output format. A filter is a small and specialized program in Linux operating system to get the meaningful input from the user / client and with the help of few other filters and pipes to perform a series of operation to get the highly unique or specified end result. It will help to process the information in a very dominant way such as shell jobs, modify the live data, reporting, etc.
Syntax of filter command:
[filter method] [filter option] [data | path | location of data]Filter Methods in Linux Operating System
Given below are different filter methods:
- Fmt
- more
- Less
- Head
- Tail
- Sed
- Find
- Grep, Egrep, Fgrep, Rgrep
- Pr
- Tr
- Sort
- Uniq
- AWK
1. Fmt
The fmt is simple and optimal text formatter. It is helpful to reformat the input data and print in end result in the standard output format.
Code:
cat site.txt
fmt -w 1 site.txtExplanation :
- In site.txt file, we are having some names. But it is in one single row and separated by space.
- The fmt command is useful to display in single line multiple words into individual records separated by space.
Output:

2. More
The more command is useful for file analysis. It will read the big size file. It will display the large file data in page format. The page down and page up key will not work. To display the new record, we need to press “enter” key.
Code:
cat /var/log/messages | moreExplanation:
- We are reading the large file “/var/log/messages” of Linux via more command.
Output:

3. Less
The less command is like more command but it is faster with large files. It will display the large file data in page format. The page down and page up key will work. To display the new record, we need to press “enter” key.
Code:
cat /var/log/messages | lessExplanation:
- We are reading the large file “/var/log/messages” of Linux via less command.
Output:

4. Head
As the name suggested, we are able to filter / read the initial or top lines or row of data. By default, it will read the first 10 lines or records of the give data. If we need to read the more lines, then we need to specify the number of lines that we need to read with the help of “-n” keyword.
Note: The record calculation will start from the top of the file or data.
Code:
head -n 7 file.txtExplanation :
- We have the sample file data having 10 records in it.
- Now we are using the default “head” command to read the data file.
- If we need to read or get the data except for default value then we will use the “-n” keyword to read the number of lines of records.
cat file.txt
Output:

head file.txt
Output:

head -n 7 file.txt
Output:

5. Tail
If we need to get the data from the bottom of the file then we will use the tail command. By default, it will read the last 10 lines or records of the give data. If we need to read the more lines, then we need to specify the number of lines that we need to read with the help of “-n” keyword.
Code:
tail -n 3 file.txtExplanation:
- We are using the default “tail” command to read the data file.
- If we need to read or get the data except for default value then we will use the “-n” keyword to read the number of lines of records.
tail file.txt
Output:

tail -n 4 file.txt
Output:

6. Sed
For filtering and transforming text data, sed is a very powerful stream editor utility. It is most useful in shell or development jobs to filter out the complex data.
Code:
sed -n '5,10p' file.txtExplanation:
- In head and tail command, we are able to filter the number of records from top or bottom.
- But if there is need to display the record form starting point to ending point.
- Then we need to use the sed command. We have 10 records in file.txt. But we need to record from line/record from 5 to 7 only.
cat file.txt
Output :

7. Find
The find filter command is useful to find the files from the Linux operating system.
Code:
find / -name "file.txt"Explanation:
- With the help of find command, we will filter out necessary files or directory in the Linux operating system.
- We need to add two main parameters in the find command i.e.
- Search path: “/” (I have provided the root directory path.)
- filename: “file.txt” (filename or directory name to filter or search)
Output:

8. Grep, Egrep, Fgrep, Rgrep
The grep, egrep, fgrep, rgrep are similar commands. It will be useful to filter or extract the matching pattern string form the input data or file.
Code:
grep -i "Davide" file.txtExplanation:
- In grep command, we need to specify the matching string in the command.
- The utility will filter out the same matching string (Davide) form the input data or file (file.txt) and display the matching record in “red” colour format.
Note: We can use the “-i” keyword in the grep command. It will help to ignore the upper case or lower case letter while filtering the data.
Output:

9. Pr
The pr command is useful to convert the input data into the printable format with proper column structure.
Code:
yum list installed | pr --columns 2 -l 40Explanation:
- In the above pr command, we are printing the output data in two columns (using ‘–columns’ keyword) and 40 lines in individual page (using ‘-l’ keyword).
Output:

10. Tr
The tr command will translate or delete characters from the input string or data. We can transform the input data into upper or lower case.
Code:
echo "www.educba.com" | tr [:lower:] [:upper:]Explanation:
- In the above tr command, we need to define the input text or data in set 1 “[:lower:]” and output data in set 2 “[:upper:]”.
Output:

11. Sort
As the name suggested, we can sort or filter the records in ascending order.
Code:
sort char.txtExplanation :
- We are having the text file (char.txt).
- It contains the number of character in a scattered way.
- Now we are using the sort command on the same file.
- After using the sorting filter on the char.txt file.
- The character will sort and display in acceding pattern.
Output:
cat char.txt

sort char.txt

12. Uniq
The uniq command is useful to omit repeated records or lines from the standard input.
If you want to display the number of occurrences of a line or record in the input file or data. We can use the “-c” keyword in the uniq command.
Code:
uniq -c char.txtExplanation:
- In char.txt file, we have the number of duplicate characters in it.
- After using the uniq command, it will remove the duplicate character and count the number of duplicate character.
Output:
cat char.txt

uniq –c char.txt

13. AWK
In awk, we are having the functionality to read the file. But here, we are using integer variables to read the file.
Below are the integer information and meaning if they are using in awk commands.
- $0: read the complete file or input text.
- $1: read the first field.
- $2: read the second field.
- $n: read the nth field.
Note: If we are not using any separator keyword “-F” in the awk command. Then the awk command considers the space in the text file or input data and separates the result as per the $variable provided in the same awk command.
Code:
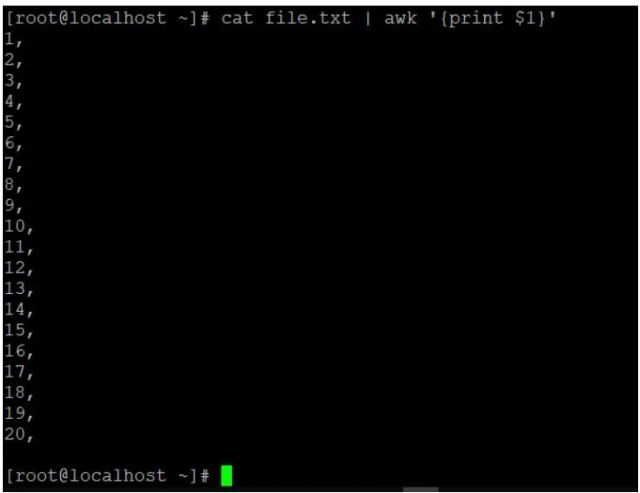
cat file.txt | awk '{print $1}'Explanation:
- In file.txt, we are having the sample data.
- If we will use $0 then entire data will read.
- If we will use $1 then only first column data will filter out.
cat file.txt
Output: Sample file view.

cat file.txt | awk ‘{print $0}’
Output: Output with “$0”.

cat file.txt | awk ‘{print $1}’
Output: Output with “$1”
grep
The grep command searches a specified file and returns all lines in the file containing a specified string. The grep command commonly takes two arguments: a specific string to search for and a specific file to search through.
For example, entering grep OS updates.txt returns all lines containing OS in the updates.txt file. In this example, OS is the specific string to search for, and updates.txt is the specific file to search through.
Piping
The pipe command is accessed using the pipe character (|). Piping sends the standard output of one command as standard input to another command for further processing. As a reminder, standard output is information returned by the OS through the shell, and standard input is information received by the OS via the command line.
The pipe character (|) is located in various places on a keyboard. On many keyboards, it’s located on the same key as the backslash character (\). On some keyboards, the | can look different and have a small space through the middle of the line. If you can’t find the |, search online for its location on your particular keyboard.
When used with grep, the pipe can help you find directories and files containing a specific word in their names. For example, ls /home/analyst/reports | grep users returns the file and directory names in the reports directory that contain users. Before the pipe, ls indicates to list the names of the files and directories in reports. Then, it sends this output to the command after the pipe. In this case, grep users returns all of the file or directory names containing users from the input it received.
Note: Piping is a general form of redirection in Linux and can be used for multiple tasks other than filtering. You can think of piping as a general tool that you can use whenever you want the output of one command to become the input of another command.
find
The find command searches for directories and files that meet specified criteria. There’s a wide range of criteria that can be specified with find. For example, you can search for files and directories that
When using find, the first argument after find indicates where to start searching. For example, entering find /home/analyst/projects searches for everything starting at the projects directory.
After this first argument, you need to indicate your criteria for the search. If you don’t include a specific search criteria with your second argument, your search will likely return a lot of directories and files.
Specifying criteria involves options. Options modify the behavior of a command and commonly begin with a hyphen (–).
-name and -iname
One key criteria analysts might use with find is to find file or directory names that contain a specific string. The specific string you’re searching for must be entered in quotes after the -name or -iname options. The difference between these two options is that -name is case-sensitive, and -iname is not.
For example, you might want to find all files in the projects directory that contain the word “log” in the file name. To do this, you’d enter find /home/analyst/projects -name “*log*”. You could also enter find /home/analyst/projects -iname “*log*”.
In these examples, the output would be all files in the projects directory that contain log surrounded by zero or more characters. The “*log*” portion of the command is the search criteria that indicates to search for the string “log”. When -name is the option, files with names that include Log or LOG, for example, wouldn’t be returned because this option is case-sensitive. However, they would be returned when -iname is the option.
Note: An asterisk (*) is used as a wildcard to represent zero or more unknown characters.
-mtime
Security analysts might also use find to find files or directories last modified within a certain time frame. The -mtime option can be used for this search. For example, entering find /home/analyst/projects -mtime -3 returns all files and directories in the projects directory that have been modified within the past three days.
The -mtime option search is based on days, so entering -mtime +1 indicates all files or directories last modified more than one day ago, and entering -mtime -1 indicates all files or directories last modified less than one day ago.
Note: The option -mmin can be used instead of -mtime if you want to base the search on minutes rather than days.
Conclusion
We have seen the uncut concept of “Linux Filter Commands” with the proper example, explanation and command with different outputs. Basically filter utility comes with Linux operating system but some third party filter utilities we can install in the operating system. The filter data is very important while developing any code or shell job on Linux or any other platform. With the help of filter command or utility, we can able to extract the valuable data from the input data.


